Sommaire de l'article
Précédemment, nous avons vu comment Cambridge Analytica / SCL jouait avec les données pour viraliser l’extrême-droite ; on voyait déjà que l’entreprise se basait sur les connaissances en psychologie (notamment sociale) pour comprendre comment « allumer un feu » sur les réseaux sociaux. Aujourd’hui, on se centre plus particulièrement sur le rôle des chercheurs en psychologie. Comment leurs recherches sur la personnalité ont-elles pu devenir une opération de manipulation politique à grande échelle sur Facebook ?
La totalité du dossier ici en PDF : CA.pdf ; ou en epub : CA.epub
Les articles précédents de ce dossier :
L’entrée de la psychologie à SCL/CA
On a vu précédemment que Wylie (doctorant en machine learning1) s’occupait de la direction des recherches à SCL/CA, mais il n’a pas été le seul à concevoir la machine de prédiction de la personnalité utilisée par CA. Il travaillait avec Tadas Jucikas docteur en biologie computationnelle2, qui a créé le système automatisé de collecte de données de CA, couplé à un dispositif algorithmique à base de deep learning3. Dans l’équipe, se trouve Brent Clickard, docteur en psychologie à Cambridge : c’est en partie lui qui fera le pont entre SCL et les professeurs de Cambridge spécialisé en psychométrie4, dont Aleksandr Kogan, psychologue social.

Kogan travaille déjà en tant que chercheur en collaboration avec Facebook, notamment sur les émotions, l’altruisme, les liens amicaux entre personnes de différents pays, et l’impact de ces liens sur les donations lors de catastrophes. Selon Kogan « l’entreprise était très ouverte à ce qu’on joue avec ses données« , le management de Facebook laissait ses employés ouvrir la porte à ce jeu, parce que cela « les rendait heureux5« .
SCL est intéressé par les compétences de Kogan et lui fait signer un premier contrat pour participer au projet Trinité de 2014, profilage psychographique criminel via l’interception des données de la population et leur analyse. Son rôle aurait été d’apporter son expertise pour modéliser un ensemble de structures psychologiques associées à un comportement déviant, antisocial6. En échange de ce travail, il négocie l’accès aux données des 1,3 millions de trinidadiens pour ses propres recherches.

Kogan s’intéresse rapidement à ce que SCL/CA trafique aux États-Unis, où il y a déjà un modèle algorithmique, mais pour lequel il manque à l’équipe des variables permettant de prédire des caractéristiques psychologiques. Leurs données socio-démographiques permettent déjà de prédire par exemple les revenus, donc le statut économique. La fréquentation de tel type de supermarché, la localisation en sont des bons indicateurs (ce serait par exemple la différence entre une personne faisant exclusivement ses courses au Biocoop VS une autre personne exclusivement à Lidl ou Aldi, on se doute bien qu’il ne s’agit pas de personnes ayant le même statut économique).
Kogan fait rencontrer à SCL Michal Kosinski et David Stillwell, dont l’étude de 2013 est particulièrement connue, je suis même tombée dessus dans un manuel sur la psychologie de la personnalité7.

L’étude de Kosinski
Dans cette étude de 20138, les chercheurs avaient proposés aux utilisateurs de Facebook de participer à divers questionnaires9 et ils ont mis tout cela en relation avec leurs pages Facebook (notamment leurs likes). Sur 90% des personnes, des associations sur la base de régressions linéaires ont été faites entre leur données des questionnaires et leurs likes, et pour les 10% des personnes restantes, ils ont tenté de prédire leur personnalité, mais aussi l’intelligence, le genre, l’orientation sexuelle, la religion, s’ils étaient blancs ou noirs, leur consommation d’alcool, etc. Et la prédiction a assez bien marché :
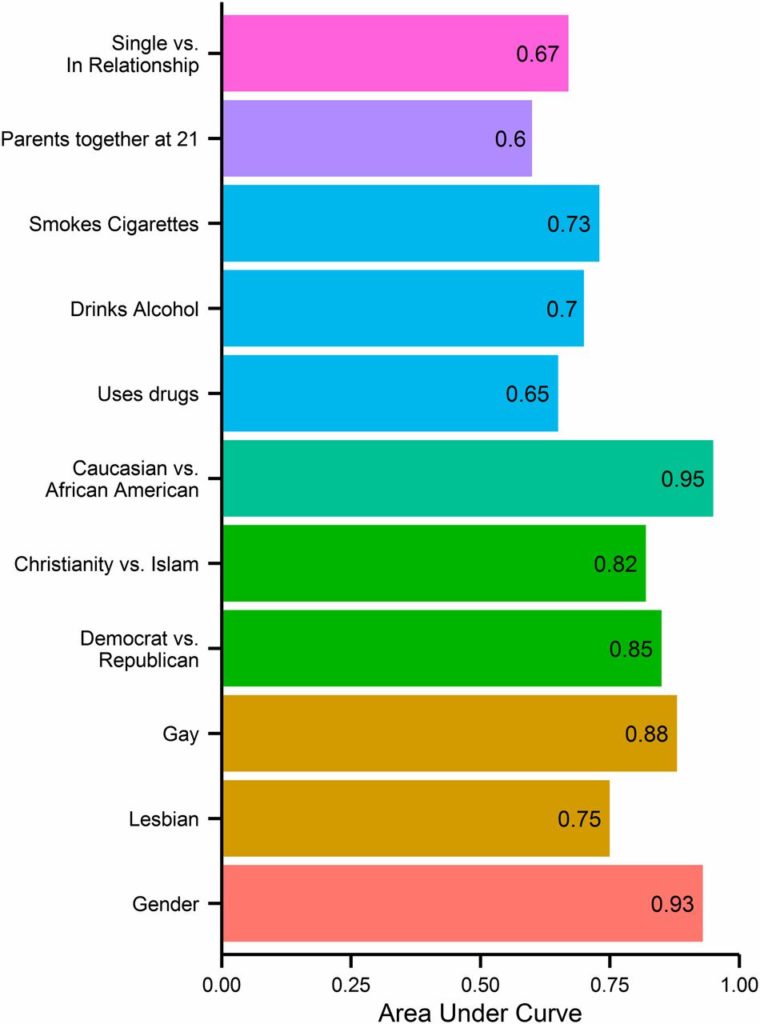
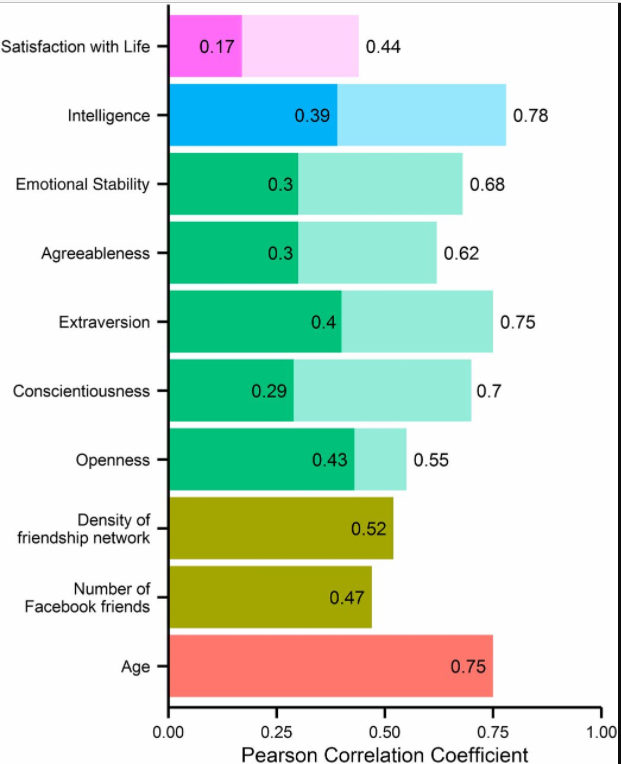
Dans le détail, on voit qu’il y a certains points évident entre les likes et le fait de deviner si par exemple quelqu’un est démocrate ou républicain (il aura liké des pages de républicains ou de démocrates), un chrétien ou un musulman aura liké des pages liées à sa religion. D’autres associations sont plus subtiles mais là aussi assez humainement prédictible de ce qu’on sait des big five (les bas agréables auront likés des pages comme « je déteste tout le monde »). Et d’autres associations sont carrément étranges et je ne pense pas que quelqu’un de sérieux s’avancerait à faire des prédictions comme « les fumeurs aimeront les pages « vivement l’été » ». L’algo permet de voir des associations que personne n’aurait osé tester tant elles paraissent étranges.
Cependant, il y a un problème, selon le papier de l’étude il y aurait eu 58 000 participants. Selon le manuel en français dans lequel j’ai vu cette étude10 ainsi qu’une autre source, il y aurait eu 11, 6 millions.
Est-ce que je me serais trompée de recherches ? Stillwell et Kosinski se retrouvent à la liste d’auteurs d’autres papiers la même année, on trouve une étude utilisant encore des échantillons d’utilisateurs de Facebook (75 000), étudiant cette fois les expressions et termes, notamment associés à la personnalité12.
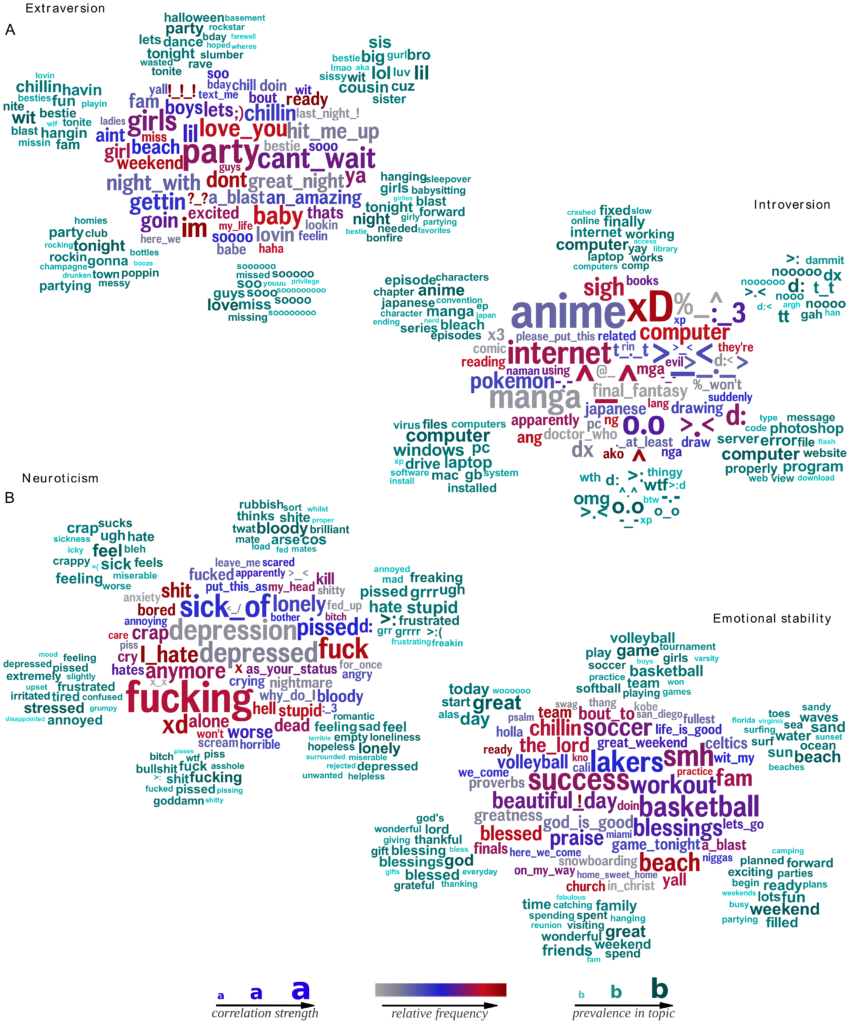
SCL/CA est très intéressée et veut que Kosinski et Stillwell reproduise cela pour eux : les chercheurs expliquent qu’il suffit de payer quelques dollars chaque personne afin qu’elles remplissent les questionnaires de l’application Facebook, avec en prime toutes les données des amis de ce premier échantillon qui seront pompées sans leur consentement direct. Et un utilisateur pouvant avoir parfois des centaines d’amis, les données peuvent se multiplier de façon massive, ce qui expliquerait ce chiffre de 6 millions. Cela est confirmé par une autre source13, qui répète ce chiffre de 6 millions en disant que seul 30 à 40% de l’échantillon avait choisi de partager ses données (contrairement aux profils des amis « pompés » par les fonctionnalités Facebook de l’époque), et c’est pour cela que les papiers de recherche s’en tiennent au chiffre de 58 000 participants, c’est la proportion de gens qui avait consenti.
SCL/CA est prêt à investir ce qu’il faudra pour reproduire cette expérience à leur profit, c’est-à-dire d’une part le fait de capter toutes ces datas, et d’autre part d’avoir un modèle de prédiction sur des variables psychologiques telle que la personnalité. Rappelez-vous aussi que la détection politique du modèle est aussi celle qui est la plus solide (.85 de corrélation entre valeurs réelles et celles prédites, ce qui est une grosse corrélation). Kosinski accepte si l’entreprise le paye un demi-million de dollars en avance et qu’ensuite CA donne 50% de toutes les royalties issues de l’exploitation des données récoltées. Nix le PDG refuse parce qu’il n’est pas sûr que cela puisse marcher, ce qu’ils vont faire du modèle n’est pas encore certain, c’est un investissement trop risqué.
Kogan propose alors un autre deal à SCL/CA : il est ok de reproduire l’expérience de Kosinski pour eux, il demande juste de l’argent pour payer ce premier échantillon et demande en échange juste le droit d’exploiter toutes les données et le modèle pour ses propres recherches. Cette fois, le deal est accepté.
Kogan crée avec un partenaire et sous la demande de Nix une entreprise qui se nomme GSR (global science research) et qui permet de recevoir les 800 000 dollars qui ont permis de recruter les premiers testeurs de « this is your digital life » une app qui contient un questionnaire de personnalité sur la même base que Kosinski (le test IPIP NEO) et quelques autres variables , puis le modèle d’analyse est reproduit. Rien n’indique que c’est SCL/CA, donc une entreprise aux fins de campagne politique, qui aura le bénéfice majeur de ces données, Kogan indique dans les conditions d’utilisations de This is your digital life « nous utilisons cette app pour nos recherches et pour comprendre comment les gens de Facebook et leur données peuvent prédire différents aspect de leur vie14« . Kogan s’en est défendu devant le Parlement anglais en disant que cela a servi un moment ses recherches, mais les parlementaires ont rappelé que ces données avaient prioritairement pour but d’être exploitée pour des fins politiques. Il a aussi argué que c’était la mode à l’époque, « c’était une pratique normale d’avoir des conditions d’usage du service très générales15« . Au Sénat américain16, il dira que c’est Wylie qui les as rédigés.
Non seulement Kogan (et Wylie) ment par omission aux participants de cet échantillon, Facebook permet aux concepteurs d’app de pomper des données d’amis qui n’ont rien demandé et n’ont rien fait avec l’app en question, mais en plus l’exploitation politique n’a rien de partial et ne servira qu’à mobiliser pour les républicains ou à démobiliser les démocrates.
Au parlement anglais, lorsque les parlementaires lui demandent s’il se rendait compte qu’il travaillait pour des politiciens aux projets « méchants17« , Kogan répond qu’il ne voulait pas voir ni savoir à l’époque. Même s’il n’était pas d’accord avec leur position, les positions de ces politiciens lui semblaient raisonnables ; il argue que la science lui a appris à faire attention avant de juger.
À une interview avec la BBC radio 4 (ci-dessous en vidéo), avant son entretien avec le Parlement anglais, il a dit l’inverse concernant Trump :
« Si vous aviez su que vos données auraient servi à la campagne de Trump, comment vous seriez-vous senti ? Ce serait absolument horrible, Mr Trump n’est pas quelqu’un dont les valeurs s’alignent aux miennes”
Fin 2014 Rust, chercheur à Cambridge, commence à craindre que les travaux de Kosinski (dont les données) soient regroupés avec ceux de Kogan. Il commence à tirer la sonnette d’alarme à ce moment-là18, notamment en fournissant des documents au Guardian, ce qui a fait bannir Kogan de Facebook. En 2015, les app sont suspendus, ainsi que d’autres du même genre (« you are what you like », « apply magic sauce » – pour cette dernière on peut l’utiliser encore si on le souhaite, en téléchargeant ses données Facebook, ou en donnant l’accès de l’app à Twitter). Ce premier scandale de 2015 s’arrête rapidement puisque l’équipe de SCL/CA dit qu’elle n’utilise plus ces données de Facebook, qu’elles ont été supprimées. Facebook n’a rien fait d’autre que de leur demander de supprimer, ils n’ont pas vérifié (c’est techniquement difficile à vérifier, étant donné qu’il est possible de les copier et de les stocker n’importe où). SCL/CA a en fait continué d’exploiter ces données.
Quand Kogan lance l’alerte sur un lanceur d’alerte
Wylie quitte CA vers fin 2014, crée Eunoia Technologies avec l’ex-équipe de CA, à savoir Brent Clickard, Tadas Jucickas et d’autres. Kogan y travaillera aussi. Eunoia fait le même travail que CA et apparemment Wylie aurait voulu créer, selon ses propos, « le rêve mouillé de la NSA ».
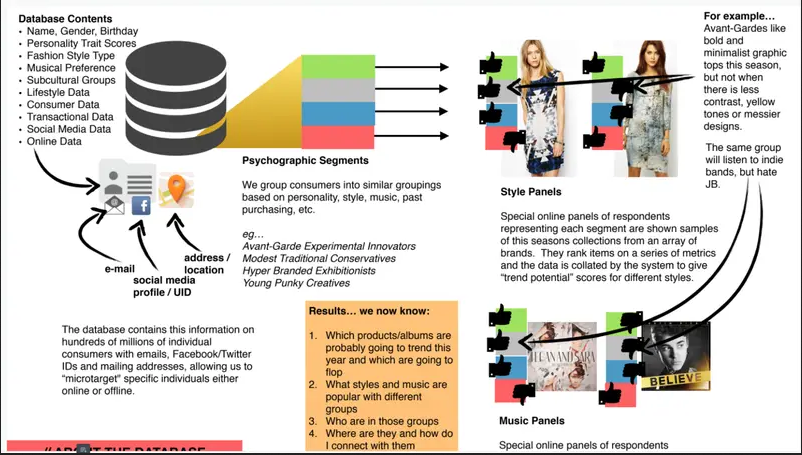
Bien que l’avocat de Wylie dit qu’Eunoia n’avait aucune donnée, ce n’est pas ce qu’affirme Kogan :
« Enfin, GSR [l’entreprise de Kogan] a conclu un accord avec Eunoia (la société de Chris Wylie) à l’été 2014 pour fournir les données de l’application GSR à Eunoia en échange de l’obtention d’autres ensembles de données commerciales d’Eunoia. En vertu de cet accord, GSR a fourni à Eunoia une copie de toutes les données de l’application GSR pour les personnes qui ont signalé leur emplacement aux États-Unis ainsi que des analyses de personnalité GSR sur certaines des données. Après qu’Eunoia n’ait pas fourni les données promises à GSR, GSR a demandé à Eunoia de détruire les données de l’application GSR qui avaient été transférées. Pour plus de clarté, il existe une différence substantielle entre les données fournies par SCL et la société de M. Wylie. SCL n’a jamais eu accès, du moins par GSR, aux données brutes de Facebook contenant tous les Likes. SCL n’a reçu que des informations démographiques (si disponibles, nom, date de naissance, lieu (ville et état), sexe) et des prédictions de personnalité et, plus tard en 2015, l’ensemble limité de 500 pages « J’aime » spécifié en 2015, représentant 4 % de l’ensemble des J’aime. Ceci est en contraste avec le contrat avec l’entité Eunoia de M. Wylie, où Eunoia a reçu toutes les pages comme les données ainsi que les dyades. »
À noter qu’il y a aussi une fuite d’une partie des données récoltées par Kosinski :
« [les] Informations personnelles exposées […] donnaient accès aux scores de personnalité « Big Five » de 3,1 millions d’utilisateurs. […] Les informations d’identification ont également permis d’accéder à 22 millions de mises à jour de statut de plus de 150 000 utilisateurs, ainsi qu’à des détails tels que l’âge, le sexe et le statut relationnel de 4,3 millions de personnes. […] Les enquêtes de Facebook et du Commissariat à l’information devraient tenter de déterminer qui a accédé aux données de myPersonality et à quoi elles ont servi. Cependant, comme il a été partagé avec tant de personnes différentes, il sera très difficile de suivre tous ceux qui en ont une copie et ce qu’ils en ont fait. Nous ne saurons jamais exactement qui a fait quoi avec cet ensemble de données. «
Huge new Facebook data leak exposed intimate details of 3m users | New Scientist https://www.newscientist.com/article/2168713-huge-new-facebook-data-leak-exposed-intimate-details-of-3m-users/
Cet ensemble de données pouvait être consulté d’une façon qui était anonymisée (on ne pouvait pas retrouver des individus, cependant au vu de la quantité de données, les experts doutent de la solidité de ce processus d’anonymisation) pour les personnes considérées comme « collaborateur » du projet. Ainsi 280 personnes y ont eu accès en partie, que ce soit dans le champ académique, mais aussi auprès d’entreprises comme Facebook, Google, Microsoft et Yahoo. Il était extrêmement facile d’y accéder car un nom d’utilisateur ainsi qu’un mot de passe traînait sur Internet, laissé là pour un projet universitaire entre étudiants et chercheurs. À noter que Kosinski et Stillwell étaient aussi dans une société qui vendait l’accès à un outil de ciblage publicitaire basé sur la personnalité (Cambridge Personality Research), construit à partir des ensembles de données de leur recherche et qui se vantait de « lire dans les pensées19 » des utilisateurs. C’est assez ironique, car leur papier de 2013 était centré sur le fait d’alerter sur l’utilisation des données. Mais ce n’est pas non plus si étonnant car Kogan dit à un moment aux parlementaires que l’université de Cambridge encourageait ses chercheurs à vendre, tirer profit de leur travail.
Cependant, rassurez-vous, cette modélisation entre données et personnalités ne sert à rien, qu’elle vienne de CA ou d’ailleurs, ce n’est que de « l’huile de serpent ».
Tout ça, c’était inutile… ???
C’est ce qu’a affirmé Kogan à plusieurs reprises devant les parlementaires anglais et devant une commission sénatoriale étasunienne. La prédiction de la personnalité à partir des données, ça ne marche pas, et ce qu’avait fait CA aurait été stupide selon ses propos :
» L’idée que ces données sont précises, je dirais que c’est scientifiquement stupide ; et dire qu’avec plus de données vous pourriez les rendre plus précises, c’est aussi assez stupide, même si vous avez des corrélations hautes. […] Si le but est le microciblage en utilisant des pubs Facebook, ça n’a pas de sens »
Guardian News, Cambridge Analytica’s Aleksandr Kogan faces parliamentary questions, 2018. https://www.youtube.com/watch?v=CE0J74PDDgQ
Pour lui, il serait plus efficace de cibler 100% de la population plutôt que 15%, et il explique une méthode à son sens plus efficace : il suffirait de faire passer un questionnaire de personnalité à un échantillon conséquent, sélectionner par exemple les plus extravertis si ce sont eux qu’on veut cibler, donner leurs adresses mail au service de pub de Facebook et employer une fonctionnalité qui permet de construire le type d’audience que sont ces personnes. Autrement dit, ce sont les algorithmes de Facebook qui se chargeront de cibler 100% des extravertis en s’inspirant des profils qu’on leur a fournis.
Au Sénat américain, un expert connaissant apparemment plus les rouages internes propre à Facebook a confirmé que Facebook était à ce titre effectivement beaucoup plus puissante que n’importe quel Cambridge Analytica.

Les parlementaires ont donc été très surpris :
« MP : Donc quel était la valeur du projet que vous faisiez pour SCL ?
Kogan : Compte tenu de ce qu’on sait maintenant, rien. […]
MP : Vous dites que c’était sans valeur ?
Kogan : Si c’est pour utiliser les pubs Facebook, c’est juste une façon incompétente de le faire. »
Guardian News, Cambridge Analytica’s Aleksandr Kogan faces parliamentary questions, 2018. https://www.youtube.com/watch?v=CE0J74PDDgQ
Et c’est là à mon sens qu’il faut être bien attentif aux propos de Kogan : d’une part, il dit au Sénat que les accusations de psyops et tout ce qu’on charge sur CA relève de la science-fiction (alors qu’il a vu et bénéficié du projet Trinité qui relève tout de même d’une surveillance de masse inquiétante), puis il centre le problème comme si CA ne faisait qu’une activité « classique » de marketing politique, c’est-à-dire rechercher un groupe à cibler afin de les mobiliser/persuader/engager via la publicité Facebook. Il ne rejette pas l’intérêt de tester une cohorte qui sert de référence pour savoir qui cibler, c’est juste qu’il trouve stupide d’avoir son propre modèle de prédiction et qu’il ne sert à rien d’avoir une quantité massive de données, alors que Facebook peut modéliser avec plus d’exactitude et a accès à l’intégralité des données de ses utilisateurs.
Autrement dit, il n’incorpore pas dans son analyse le fait de s’appuyer sur la recherche de la personnalité (mais aussi les tests concernant les biais qui « fonctionnent » ainsi que d’autres caractéristiques telle que la triade noire) pour, certes, effectivement faire appel à la pub, mais aussi pour créer des fausses pages qui vont immanquablement attirer ces profils et les regrouper. Ayant la main mise sur ces pages, CA/SCL a pu bombarder les cibles d’infos tel qu’ils le souhaitaient. Ils ont pu créer ses infos, former des récits d’influence particulier. On le voit bien avec l’affaire Trinité, où effectivement ils n’ont pas eu du tout besoin du modèle de personnalité, mais seulement des données « âge » (ils ciblaient tous les jeunes), puis ils ont crée un mouvement d’abstention de toutes pièces qui s’est ensuite viralisé spontanément. Ce chemin d’influence, plus sournois, mais qui exploite tout autant les données directes que celles calculées de la personnalité, Kogan n’en parle pas et il ne me semble pas que quiconque l’ait poussé à en dire plus dessus. Pourquoi ? Aux États-Unis, à force de voir les commissions parlementaires, on comprend vite que tous les partis se servent de ces méthodes de ciblage, que la récolte massive de données est un « acquis » et que c’est valorisé d’un point de vue économique ; chez les républicains, c’est à ce point que le fait de réglementer les lois à ce sujet choquent les sénateurs comme si on parlait d’installer un régime stalinien. Selon eux, ce serait entraver une saine compétition menant à une innovation qu’ils ne cessent de vanter. Quand Zuckerberg affirme très simplement qu’il est ok avec le fait de réglementer aux USA, comme cela se fait en Europe avec la RGPD, les sénateurs le font répéter tant ça leur paraît hallucinant qu’on puisse être « pour » une telle réglementation.
Tout ça pour dire qu’aux USA leur niveau de tolérance de l’exploitation des datas n’est pas le même que le nôtre en Europe : pour eux, c’est normal, c’est bon pour l’économie et l’évolution du pays, il n’est pas question non plus que Facebook « censure » ce qui pourrait avoir été repéré comme de la désinformation, parce que ça serait selon eux une atteinte à la liberté d’expression (le rapport à la liberté d’expression est très différente par contraste avec la France par exemple). Ce que j’ai pu voir au travers des auditions aux États-Unis, c’est que bien que les démocrates aient un avis différent et prônent une réglementation et un empêchement des entreprises type CA/SCL à se comporter comme dans le Far-West, les deux bords politiques se sont tout de même accordés sur le fait de punir Facebook, de voir Facebook comme responsable de l’affaire Cambridge Analytica.
Alors, est-ce que vraiment, comme l’affirme Kogan, le scandale Cambridge Analytica ne serait qu’un mythe de science-fiction et que les chercheurs en psycho’ auraient arnaqué cette entreprise et d’autres avec leurs méthodes psychographiques et modèles de déduction de la personnalité qui ne serait que de « l’huile de serpent » ? En étudiant cette question, on va en profiter pour explorer tous les arguments affirmant que l’affaire Cambridge Analytica ne serait pas si scandaleuse, qu’au fond on aurait amplifié son rôle et son influence quant aux affaires qu’on lui a associé.
A suivre : Pourquoi l’affaire CA est bien une manipulation se basant sur la prédiction de la personnalité
Notes de bas de page | Sources
1Ou « apprentissage automatique » c’est une sous-catégorie du domaine scientifique de l’intelligence artificielle. Cela consiste à s’occuper d’algorithmes découvrant des patterns, c’est à dire des schémas récurrents dans des ensembles de données.
2Un champ qui analyse et modélise des masses de données issue de la biologie, développe des nouvelles méthodes d’analyse.
3Ou « apprentissage profond », il s’agit d’une pratique d’intelligence artificielle de machine learning qui passe par le déploiement d’un réseau de neurones artificiels.
4Mesure des caractéristiques psychologiques des individus.
5Propos de Kogan aux parlementaires anglais : https://www.youtube.com/watch?v=CE0J74PDDgQ
6Peut-être est-ce là qu’il a la première fois utilisé son API mesurant la triade noire conçue avec des chercheurs de St-Petersbourg ? C’est juste une possibilité que je soulève parce que l’utilisation de ces variables m’interroge depuis le précédent article, étant donné que cette mesure a été utilisé ensuite pour mobiliser sournoisement l’alt-right, à coup de fausses pages Facebook et d’organisation de rassemblement IRL.
7Psychologie de la personnalité, Michel Hansenne, 2021.
8Private traits and attributes are predictable from digital records of human behavior Michal Kosinski, David Stillwell, Thore Graepel 2013 https://www.pnas.org/content/110/15/5802
9Le test se nommé « My personnality », la personnalité y est mesurée avec le IPIP, l’intelligence avec des matrices de Raven, la satisfaction de vie a été aussi mesurée.
10Psychologie de la personnalité, Michel Hansenne, 2021.
12Personality, Gender, and Age in the Language of Social Media: The Open-Vocabulary Approach H. Andrew Schwartz, Johannes C. Eichstaedt, et coll., 2013 https://www.scinapse.io/papers/2119595472
14Rapporté par les parlementaires anglais ici : https://www.youtube.com/watch?v=CE0J74PDDgQ
16https://www.c-span.org/video/?447132-1/senate-committee-examines-cambridge-analytica-partnership-facebook
17« Nasty » ; ce n’est pas une qualification si déplacée de la part des parlementaires anglais, rappelons qu’on parle de politiciens pour certains hautement homophobes voulant enlever des droits aux gays. Même les républicains s’en méfiaient, surtout à l’époque où Kogan et Wylie étaient en contact avec eux.
Dans la partie « Quand Kogan lance l’alerte sur un lanceur d’alerte », je crois que la traduction française de « wet dream » c’est plutôt « rêve mouillé » :p
merci, c’est corrigé !
« Rêve mouillé » : la traduction la plus fréquente de cette expression est « éjaculation nocturne » !! Evidemment cela n’aurait pas de sens, la traduction la plus appropriée en serait à mon avis « projet chimérique ».
[…] Quand la psycho sert à manipuler sur Facebook (hacking-social.com) […]
[…] Quand la psycho sert à manipuler [CA6] […]